firemail
标题: 理解WebKit和Chromium:Chromium资源磁盘缓存 [打印本页]
作者: Qter 时间: 2021-9-23 13:32
标题: 理解WebKit和Chromium:Chromium资源磁盘缓存
## 概述
想象一下,如果没有磁盘缓存的世界。当用户访问网页的时候,每次浏览器都需要从网站下载网页,图片,JS等资源,这其实费力又不讨好。解决这一问题的方法就是将之前浏览器下载的资源保存下来,存到磁盘中,以备今后使用。当然,资源有时效性,也会变的不再有效,所以有相应的退出机制来解决这一问题。在现代浏览器中,绝大多数浏览器都有磁盘缓存机制,因为它确实能够提高网页的加载速度,能够省去了网络的时间。
## 特性
为了适应的网络资源的本地缓存需求,Chromium的磁盘本地缓存有几个特性或者要求:
第一,磁盘空间不是无限大的,虽然需要缓存的资源可能很多,所以必须要相应的机制来移除合适的缓存资源,以便加入新的资源。
第二,能够处理浏览器崩溃时候不破坏磁盘文件,至少能够保护原先在磁盘中的数据。
第三,能够高效和快速的访问磁盘中的现有数据结构,支持同步和异步两种访问方式。
第四,能够避免同时存储两个相同的资源。
第五,能够很方便的从磁盘中删除一个项,同时可以在操作一个项的时候不受其它请求的影响。
还有些其它的特性,这里不再一一介绍。这些既是磁盘本地缓存的需要,同时也是Chromium的设计目标,让我们一起看看下面介绍的结构是如何做到这些的。
## 结构
在理解内部结构之前,我们来看一看对外的接口设计。笔者认为这个接口设计很清晰简单(跟Chromium中的一些其他接口比较),有两个类,Backend和Entry。Backend表示整个磁盘缓存,所有针对磁盘缓存操作的主入口,表示的是一个缓存表。Entry类指的是表中的表项。缓存通常是一个表,对于整个表的操作作用在Backend上,还包括创建表中的一个个项,每个项是关键字来唯一确定,这个关键字就是资源的URL。而对项目内的操作,包括读写等都是由Entry类来处理。读者可以通过在地址栏输入“ chrome://view-http-cache/”来查看这些项。下图是一个表项的内部存储内容。
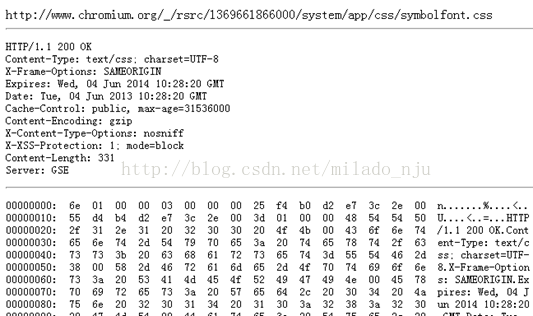
下面介绍表和表项是如何被组织和存储在磁盘上的。在磁盘上,Chromium至少需要一个索引文件和四个数据文件。索引文件用来检索存放在数据文件中的众多索引项,用来索引表项。数据文件又称为块文件,里面包含很多特定大小的块(例如256字节或者1k字节),用于快速检索,这些数据块的内容是表项,包括HTTP文件头,请求数据和资源数据等等,数据文件名形如“data_1”,“data_2”等。
当资源文件大小超过一定值的时候,Chromium建立单独的文件来保存它们,而不是将它们方式上面的4个数据文件中。这些单独文件没有元数据信息,只是资源文件内容,而文件名形如“f_xxxxx”,其中xxxxx是5个数字或者ABCDEF(16进制),用于表示编号。
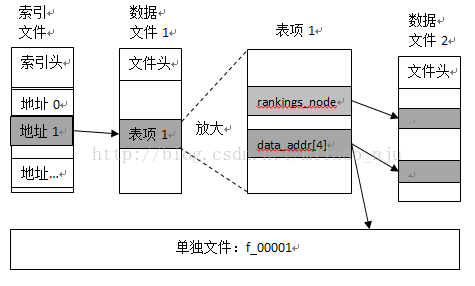
索引文件的结构定义包括一个索引的头部和索引地址表。头部用来表示该索引文件的信息,例如索引文件版本号,索引项数量,文件大小等等信息。而索引地址表就是保存各个表项对应的索引地址。该索引文件是直接将文件映射到内存地址,这样可以快速的找到表项的索引地址。索引地址的含义以下面两个例子作如下解释:
0x8000001C: 前四位的8表示这个地址指向的表项是一个单独的文件(说明内容大于特定值),后面20位表示文件的名字中的编号,所以文件名为”f_0001C”。
0xA0020001: 前四位的A表示这个地址指向的表项是存入数据文件”data_2”的第一个块。
这些表示可能不是固定地,以后也可能发生改变,但是基本思想还是这样。数据文件的结构总体上也是类似,它也是一个文件头加上后面的块文件。前面说过,每个块大小是固定的,例如512字节,所以当需要超过512的时候,可能会为其分配多个块来解决这一问题。但是,最多不能够超过四个块(前面说过大于这个通常是单独的文件)。另一方面,如果一个表项需要分配四个块,则通常是跟块在文件中的索引位置是对齐的,也就是起始块的位置是4的倍数。
表项的结构也分为两个部分,第一部分用于标记自己,包括各种元数据信息和自身的内容,通常它是较少变动得,Chromium中用disk_cache::EntryStore表示。另一部分是经常发生变动,Chromium中用disk_cache::RankingsNode表示,它的大小固定,主要是为了表项的回收算法服务的,里面保存了回收算法所需要的信息。EntryStore结构可以查阅代码。它有一些标记该表项的数据,例如“hash”,“key”等。”key”其实是资源的URL,如果URL过于长,那么”long_key”是就派上了用场,可以用一个或者多个块来存储。”data_addr”可以存储多达4个地址,它们指向不同的位置,这些地址可以表示HTTP头,资源内容等。
总结上面的描述,可以描绘出磁盘缓存的存储结构如下图所示。
Chromium使用LRU(Least RecentUsed)最近最少使用算法来回收表项。因为磁盘存储的空间是优先的,不能无限的增长下去,所以对于很少使用到的表项,回收这一部分磁盘空间。
## 参考资料
1.http://www.chromium.org/developers/design-documents/network-stack/disk-cache
作者: Qter 时间: 2021-9-23 14:08
本帖最后由 Qter 于 2021-9-23 14:32 编辑
https://blog.csdn.net/chuanglan/article/details/103357375
http://www.rrdaj.com/hzseo/yi-dong-duan-seo/3064.html
在本文中,我们将解释浏览器如何使用其缓存(包括 memory cache vs disk cache)更快地加载页面,哪些因素决定缓存持续时间,以及我们如何在必要时绕过缓存。为什么缓存很重要?这个我就不多说了,大家可以去搜下,看看我写的其他缓存类的文章即可!浏览器缓存的工作原理就是–用户从未访问过到再次访问你的网站的过程中,浏览器将从Web服务器检索HTML页面,然后查询其静态资源(JavaScript,CSS,图像)的缓存。
浏览器到底到底是怎么知道在缓存什么呢?目前主流的浏览器缓存分为两类–强缓存和协商缓存
一、协商缓存
浏览器检查Web服务器生成的HTTP响应的标头,一般用于缓存的标题有四个:
- ETag
- Cache-Control
- Expires
- Last-Modified
一、ETag
ETag是作为一个缓存验证令牌的字符串,这通常是文件内容的hash值。服务器可以在其响应中包括ETag,然后浏览器可以在请求中使用它(在文件过期之后),以便确定缓存是否包含过时的副本。如果hash相同,则资源未更改,服务器就以304状态码(未修改)来响应空主体,也就是说浏览器知道使用缓存副本仍然是可行的。不过要注意的是,ETag仅在文件从缓存过期时用于请求。
二、Cache-Control
所述Cache-Control头部具有一个数目,我们可以设置它的 Cache Behavior,Expiration 和 Validation,当然这些也可以组合在一起。
Cache Behavior如下:
1、Cache-Control: public
public表示资源可以被浏览器,CDN等缓存
2、Cache-Control: private
private表示资源只能由浏览器缓存
3、Cache-Control: no-store
这就告诉浏览器始终从服务器请求资源
4、Cache-Control: no-cache
这告诉浏览器缓存文件但不使用它,直到它检查服务器以验证我们有最新版本,主要使用ETag标头完成此验证。它通常与HTML文件一起使用,因为浏览器始终需要检查最新标记是有可用的。
三、Expires
1、Cache-Control: max-age=60
这指定了资源应该被缓存的时间长度(以秒为单位),也就是说它应该被缓存1分钟,建议最大值不应超过1年(max-age = 31536000)。
Cache-Control:s-max-age = 60
这仅适用于像CDN这样的中间缓存。
2、Validation (验证)
Cache-Control: must-revalidate
这表示必须在使用之前验证老旧的资源状态再缓存它,并且不应使用过期资源。
3、Expires(过期)
该过期头部信息是 HTTP 1.0,现在仍然在许多网站使用。此标头字段提供过期日期,在该日期之后就被视为无效了。
比如:Expires: Wed, 25 Jul 2018 21:00:00 GMT,如果Cache-Control中有max-age指令,浏览器将忽略此字段。
四、Last-Modified
这个标头也来自HTTP 1.0,比如:
Last-Modified: Mon, 12 Dec 2016 14:45:00 GMT
此字段说明上次修改资源的日期和时间。
HTTP缓存响应如下:
- Accept-Ranges: bytes
- Cache-Control: max-age=3600
- Connection: Keep-Alive
- Content-Length: 4361
- Content-Type: image/png
- Date: Tue, 25 Jul 2017 17:26:16 GMT
- ETag: "1109-554221c5c8540"
- Expires: Tue, 25 Jul 2017 18:26:16 GMT
- Keep-Alive: timeout=5, max=93
- Last-Modified: Wed, 12 Jul 2017 17:26:05 GMT
信息解读:
服务器使用的是: Apache
第2行告诉我们max-age是1小时
第5行告诉我们这是一张PNG图片
第7行向我们表达了ETag值,该值将在1小时标记后用于验证,以验证资源是否未更改
第8行是Expires标题,因为设置了max-age,它将被忽略
第10行是Last-Modified标题,显示上次修改图片的时间
缓存的会出现的问题
通过以上,我们已经知道浏览器缓存是非常棒的,我们应该多多利用它。但我们也希望用户在进行更新时能够看到我们页面的最新版本,我们不能指望他们每次访问我们的网站都得刷新,那不累死了,这类问题也是开发人员和用户经常遇到的。比如用户可能在浏览器中缓存了一些旧的 JavaScript,导致表单重置,而不是在点击“登录”按钮时提交。
假设我们在名为app.min.js的JavaScript文件中修复了一个 bug,并更新推送到我们的网站。
比如HTML看起来像:
<script src=”assets/js/app.min.js”>
假如我们的Web服务器将JavaScript文件的max-age设置为1周(604,800秒)则:
Cache-Control: private, max-age=604800
更新后,一些用户反映他们仍然有问题bug。怎么回事呢?原来是第一个用户在2周前访问了该网站,并有一个缓存app.min.js的缓存副本。由于副本早于max-age,浏览器从服务器检索文件,并获得最新的版本。另一个用户在2天前就访问了该网站,并且还有一个缓存app.min.js的缓存副本,这个副本比 max-age 更新,所以他的浏览器仍然很可以使用缓存副本。具体怎么解决,大家可以在我博客搜下相关文章查看!
二、强缓存:
disk cache(磁盘缓存) 和 memory cache(内存缓存)的区别?
它们也属于强缓存的一种,现在浏览器缓存存储图像和网页等(主要在磁盘上),而你的操作系统缓存文件可能大部分在内存缓存中。使用这两个缓存功能,是因为它比从远程的 web 服务器获取这些资源的方式更近、更快。Cpu 本身是有”缓存线”的,它是程序最近使用的内存(RAM)部分的副本。这样,如果一个程序在一个循环中运行(一遍又一遍地做同样的事情) ,它也就不必为每个指令或数据块进入 RAM 了。这个缓存比 RAM 快得多,但是它非常小,因为超快的内存毕竟昂贵。
强缓存作为性能优化中缓存方面最有效的手段,能够极大的提升性能。由于强缓存不会向服务端发送请求,对服务端的压力也是大大减小。对于不太经常变更的资源,可以设置一个超长时间的缓存时间,比如一年。浏览器在首次加载后,都会从缓存中读取。但是由于不会向服务端发送请求,那么如果资源有更改的时候,怎么让浏览器知道呢?现在常用的解决方法是加一个?v=xxx的后缀,在更新静态资源版本的时候,更新这个v的值,这样相当于向服务端发起一个新的请求,从而达到更新静态资源的目的。
至于区别主要在于提取速度上,memory cache 要比 disk cache 快的多,怎么使用要看前端技术人员结合自己网站来选择了,两个都是很不错的缓存方式!举个例子:从远程 web 服务器直接提取访问文件可能需要500毫秒(半秒),那么磁盘访问可能需要10-20毫秒,而内存访问只需要100纳秒,更高级的还有 L1缓存访问(最快和最小的 CPU 缓存)只需要0.5纳秒。
作者: Qter 时间: 2021-9-23 14:45
作者:rambo
链接:https://www.zhihu.com/question/64201378/answer/217831630
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先这个问题我在stackoverflow上关注了好久,就是没人回答
https://www.chromium.org/developers/design-documents/network-stack/disk-cache[url]www.chromium.org/developers/design-documents/network-stack/disk-cache[/url]
How chrome browser determine memory cache and disk cache?stackoverflow.com/questions/45497696/how-chrome-browser-determine-memory-cache-and-disk-cache
源码:
https://github.com/chromium/chromium/blob/780531da89c747e5f0359de180957bbb143b2133/net/disk_cache/disk_cache.hgithub.com/chromium/chromium/blob/780531da89c747e5f0359de180957bbb143b2133/net/disk_cache/disk_cache.h
上面 姚垚 已经对 memoryCache diskCache 运行机制进行了说明。 就不再补充
其实webkit缓存机制还有一个叫 pageCache 这里暂不讨论
讲真这个问题的标准答案,我也不知道,我也非常好奇正确答案, 期待大神的解答。 以下答案就说说我个人使用中的理解。
先来说说 内存缓存的特点 快(读取快) 时效性(进程死,他也死)
第一个现象(以图片为例):
访问-> 200 -> 退出浏览器
再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)
总结: 会不会是chrome很聪明的判断既然已经从disk拿来了, 第二次就内存拿吧 快。(笑哭)
第二个现象(以图片为例):
只要图片是base64 我看都是from memroy cache。
总结: 解析渲染图片这么费劲的事情,还是做一次然后放到内存吧。 用的时候直接拿
第三个现象(以js css为例):
个人在做静态测试的发现,大型的js css文件都是直接disk cache
总结: chrome会不会说 我擦 你这么大 太JB占地方了。 你就去硬盘里呆着吧。 慢就慢点吧。
第四个现象:
隐私模式下,几乎都是 from memroy cache.
总结: 隐私模式 是吧。 我不能暴露你东西。还是放到内存吧。 你关,我死。
编辑于 2018-12-29
赞同 535 条评论分享
收藏喜欢收起
继续浏览内容

知乎
发现更大的世界
打开

Chrome
继续

姚垚
打杂工程师
11 人赞同了该回答
谢邀
@温柔的杜小妹儿
。
对于memory cache的使用,浏览器主要是去存储一些当前获取到的资源,比如img,第一次加载的时候会去调用requestImage,根据缓存情况来判断是去add还是update还是从mc里获取。图片首次加载会去判断policy的值而add进mc。再次请求的时候,requestImage的时候判断policy值存在,就去mc读取相关缓存。
对于dist的缓存,浏览器启动的时候就会创建一个curl打头的对象,然后创建一个文件夹,读取本地缓存文件放进去。然后把文件内容用hashmap表示,请求发出,如果返回200,就去请求远端数据。如果是304,就会读取本地文件。如果文件存在,直接从本地获取。
此外还有更新的一些机制,我就不太了解了。手机打字如果有单词拼错见谅,家里电脑的zx键坏了…
编辑于 2017-08-21
赞同 1114 条评论分享
收藏喜欢
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

礁石在浪边
批评不自由,赞美无意义
40 人赞同了该回答
因为类似的问题特地找了相关的资料,写了一篇博文:由memoryCache和diskCache产生的浏览器缓存机制的思考
今天在做项目的优化的时候,使用chrome开发者工具的network发现了细节
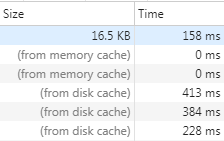
虽然这两个看起来都是从缓存中读取,但还是有一些不一样的!
webkit资源的分类webkit的资源分类主要分为两大类:主资源和派生资
http状态码200 from memory cache
不访问服务器,直接读缓存,从内存中读取缓存。此时的数据时缓存到内存中的,当kill进程后,也就是浏览器关闭以后,数据将不存在。
但是这种方式只能缓存派生资源
200 from disk cache
不访问服务器,直接读缓存,从磁盘中读取缓存,当kill进程时,数据还是存在。
这种方式也只能缓存派生资源
304 Not Modified
访问服务器,发现数据没有
更新,服务器返回此状态码。然后从缓存中读取数据。
但是这里有困惑,怎么判断from memory cache还是304
三级缓存原理1. 先去内存看,如果有,直接加载
2. 如果内存没有,择取硬盘获取,如果有直接加载
3. 如果硬盘也没有,那么就进行网络请求
4. 加载到的资源缓存到硬盘和内存
所以我们可以来解释这个现象
图片为例:
访问-> 200 -> 退出浏览器
再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)
http headermax-age
web中的文件被用户访问(请求)后的存活时间,是个相对的值,相对Request_time(请求时间)
Expires
Expires指定的时间根据服务器配置可能有两种:
1. 文件最后访问时间
2. 文件绝对修改时间
如果max-age和Expires同时存在,则被Cache-Control的max-age覆盖
last-modified
WEB 服务器认为对象的最后修改时间,比如文件的最后修改时间,动态页面的最后产生时间
ETag
对象(比如URL)的标志值,就一个对象而言,文件被修改,Etag也会修改
Cache-Control
简单理解,强缓存
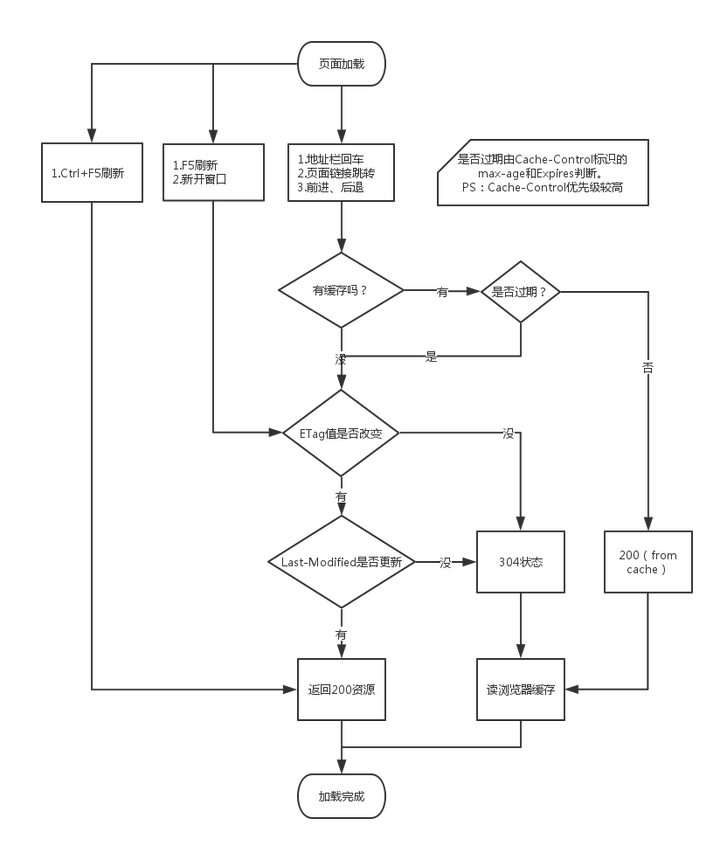
最后结论见图片(来源自网络)
编辑于 2017-09-21
https://www.zhihu.com/question/64201378
| 欢迎光临 firemail (http://firemail.wang:8088/) |
Powered by Discuz! X3 |
