https://zhuanlan.zhihu.com/p/64551643
自2017年开始,“AIoT”一词便开始频频刷屏,成为物联网的行业热词。“AIoT”即“AI+IoT”,指的是人工智能技术与物联网在实际应用中的落地融合。当前,已经有越来越多的人将AI与IoT结合到一起来看,AIoT作为各大传统行业智能化升级的最佳通道,已经成为物联网发展的必然趋势。本场chat我们一起学习什么是AIoT,如何入门AIoT开发,在人工智能物联网时代来临之前做好知识储备。 AIoT并不是新技术的革新,它之所以难以理解是因为隔行如隔山,做人工智能算法的不懂硬件,懂嵌入式的又不懂人工智能算法,不要怕,此课程会慢慢揭开AIoT的神秘面纱,让你完美地跨界迎接新的技术潮流。 什么是机器学习
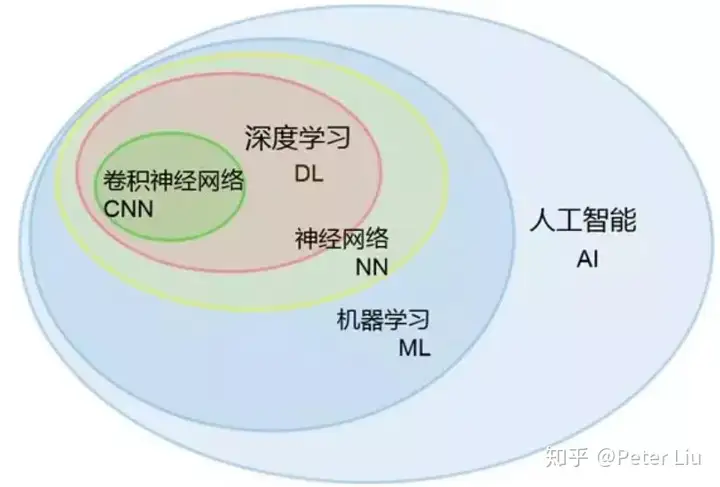 作为人工智能的子集,机器学习使用统计学技术赋予计算机学习的能力,而无需明确编程。在其最原始的方法中,机器学习使用算法来分析数据,然后根据其解读进行预测。 关键因素在于,机器经过训练,可从数据中学习,因此它能够执行给定工作。为此,机器学习应用模式识别和计算学习理论,包括概率技术、核方法和贝叶斯概率,这些专业领域技术已成为目前机器学习方法中的主流。 机器学习算法并不遵循静态程序指令,而是利用输入示例训练集来构建模型进行运算,以便做出数据驱动型预测并输出表示出来。 为了使读者更容易理解什么是机器学习,这里不讲枯燥的算法,我们以生活中的场景为例看下当前的机器学习技能: - 预测数值,学名回归。比如,给你某人的烟龄和健康状态,预测他将患肺癌的概率。这就像填空题。

- 分辨种类,学名分类。从有限的类别中选出一个。这是最常见的,像物体识别,人脸识别,都属于这种。这就像选择题,并且”都不是”并不是一个种类,而是分类失败的情况。

- 监控状态,学名异常检测。这也可看成是单分类的情况。当输入不能归为唯一的类别时就认为是异常。这就像判断题。

- 发现结构,学名聚类。用于发现大量个体的分布模式并一一列出,这就像简答题。这和分类的一个重要区别是每“簇”并没有对应的类别名称,也没有事先定好的类别数量。

- 学习策略,学名强化学习。比如让机器狗学会走路,让电脑学会下围棋,这就像实验题。这也是最常带给人类对抗和恐惧的一类应用。

有心的读者已经发现人工智能就是大量数据统计后的规律拟合,我们以一张图举例看下“从古至今”人工智能发生了哪些变化: 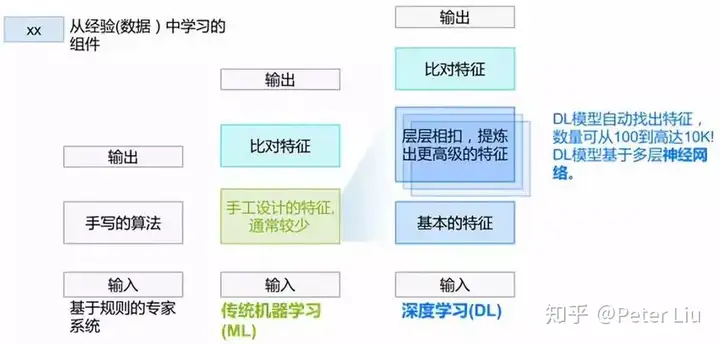 最早的AI系统是基于规则的专家系统。所谓规则,可以简单地理解为一大堆if – then -else。这些规则是听从专家的意见手写的代码。从这个角度上,我们一直在做AI——只要用户认可我们做的东西就是有智能的。专家系统的性能容易出现天花板,一个重要原因是很多经验只可意会难以言传。 后来,机器学习(ML)的出现,使我们不必再直接写规则,而是从数据中提取出一些指标或者说是特征,结合各特征的强度与重要性,就可做出预测或判断。不过,选定并提取特征是个需要反复推敲的技术活+体力活。 再后来,深度学习(DL)把提取特征的工作也接管了,通过多个神经网络层,一点点提炼出高级的特征。打个形象的比方,在做人脸识别时,从像素>线条>轮廓>五官。因此,深度学习进一步解放了人类的双手。 集成 AI 模块到硬件中我们知道人工智能对于硬件就是模型的部署,我们先把 AI 模型看成黑匣子,学习下如何把这个黑匣子集成到硬件上: 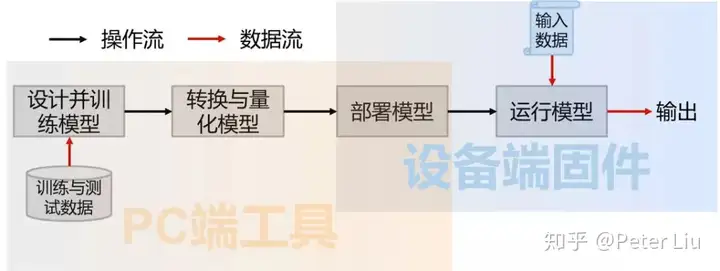 专职做算法的对 AIoT 有个误解,会觉得硬件性能这么低训练 AI 模型要到猴年马月。注意这里的 AI 模型并不在嵌入式硬件上训练,这里只是把在服务器上训练好的模型部署到嵌入式硬件上。这一点从上图可以看出,模型训练在PC端,把训练好的模型部署在设备端,本文只讲述如何集成 AI 模型到硬件上,以及如何加速 AI 的计算,让人工智能真正的落地。 模型在训练时需要加入辅助训练的结构,并且训练过程中为了提高精度,一般使用至少单精度浮点数。通常不同的训练工具(也叫框架),会使用不同的格式来表达训练出来的模型,这样的模型还需要进一步加工才能应用。 首先,要去掉辅助训练的结构,有的可以直接拿去,有的体现成了对模型参数的变换。然后, 把浮点数表达的参数和各个中间层的输出,转换成常用的8位或16位整数。一方面是因为好的模型对精度的要求其实不高,另一方面也是整数运算的代价远小于浮点数运算。这些叫做对模型的量体裁衣,也叫做模型的转化与量化。 模型优化后就可以部署到硬件上,转换模型的格式或者呈现方式,使它能对接到目标应用系统的软硬件接口上,并部署到目标设备中。目前常用的部署方法有两种: 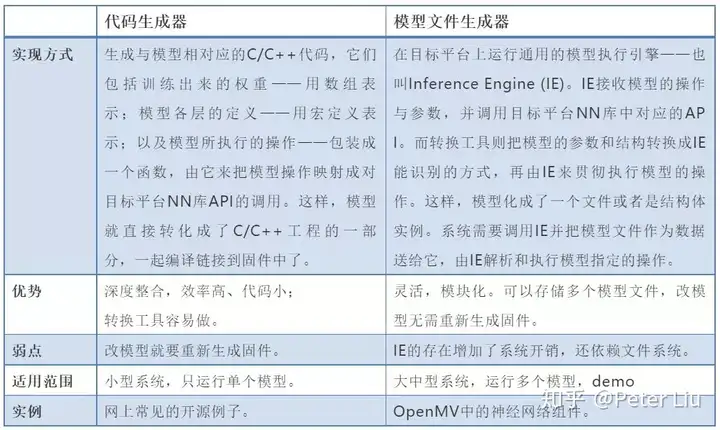 最后我们用过一张图来说明拿到训练好的模型后需要精简量化和部署执行的过程: 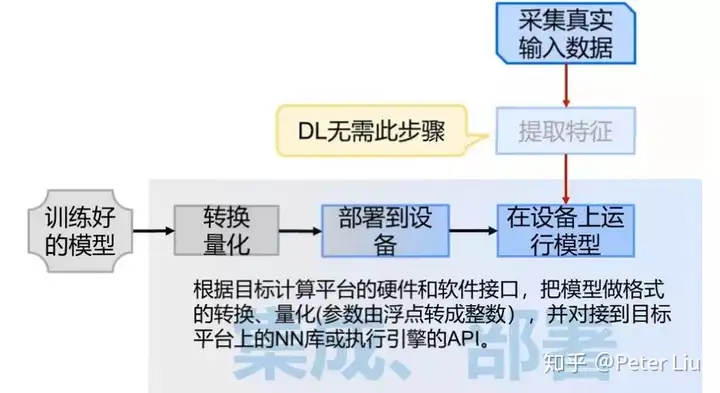
AI 模型的部署上面讲了模型的精简和部署,其中非常关键的就是AI模型的转换与部署,它贯通了训练模型与使用模型的两个世界;并且有主要的2种方式,分别是把模型转换成对接平台底层库的代码,或者是在固件里安插一个执行引擎并把模型转换成对应的指令。 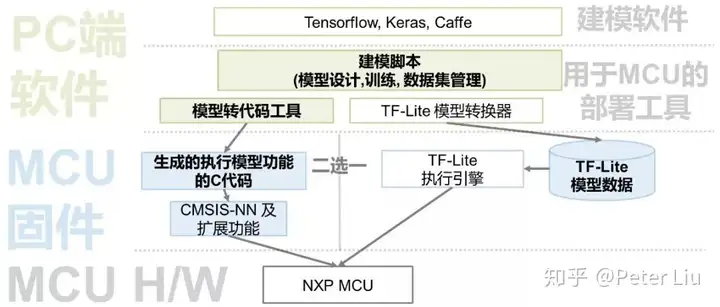 如图首先在PC上用 TensorFlow 等框架去许梿符合要求的模型,然后把模型转为代码,与CMSIS-NN结合(CMSIS-NN是arm的一个开源sdk)。另外一种就是利用模型转换器转换为嵌入式设备模型,然后通过相应引擎去部署到嵌入式设备上。下面我们详细讲下这两种方法。 - 模型转代码 在Cortex-M平台上,Arm提供了专用于执行神经网络操作的底层库,名为CMSIS-NN,它向上提供了C语言的API接口,支持常见的普通卷积、空间与通道分离的卷积,以及全连接型运算,还支持与主运算配套使用的激活、向下采样等辅助操作。这5种“积木”块的有机组合,足以构建绝大多数深度神经网络模型。 我们可以形象地把CMSIS-NN看成是一个特殊的CPU,它提供了上面5条指令,而模型则是源代码,模型转代码就是把模型“编译”成CMSIS-NN的“机器语言”。这里不详细讲解CMSIS-NN,待会会用专门一节介绍。
- 模型转中间表达 如果说上面模型转代码仿佛是编译的方式,那么把模型转换成某个执行引擎的中间表达,就像是“解释”的方式,而这个执行引擎就是解释器。 解释器既可以调用CMSIS-NN来在Cortex-M平台上提高效率,也可以内置底层NN运算库来提高通用性。因为在MCU平台上运行DL模型还基本是块新大陆,现有的执行引擎还没有针对CMSIS-NN优化,只能使用内置的通用NN库。 执行引擎的一个代表,就是Google的Tensorflow-Lite(简称TF-Lite)。TF的大名想必早已如雷贯耳,但这个TF-Lite却不是一个简化版的TF,而只是一个执行引擎,最主要的就是它不带有训练模型的功能。 Google提供了名为“toco”的工具,用于把TF模型(pb格式的文件)转换成TF-Lite能解释的中间表达。在集成到MCU时,把转换后的文件展成C数组定义或者放在SD卡中,并且把TF-Lite编译链接进MCU端的固件,就可以使用它了。
CMSIS-NN介绍Arm推出了基于Cortex-M核的优化方案,名为CMSIS-NN。CMSIS的全称是Cortex Microcontroller Software Interface Standard ( Cortex微处理器软件接口标准),目的就是为了解决微处理器生态中软件无法兼容的问题。 目前微控制器上的软件操作系统非常分散,相应的软件无法很好的复用,存在大量的重复造轮子的现象。而Arm所引入的CMSIS框架,做到了一种一统江湖的感觉,通过引入一系列极简的抽象层API,将应用程序、中间件同OS进行隔离而不会影响系统的性能,同时又很友好地提供了对于主流调试器DS-5/KEIL/IAR等的支持。 下面是CMSIS的软件框架图: 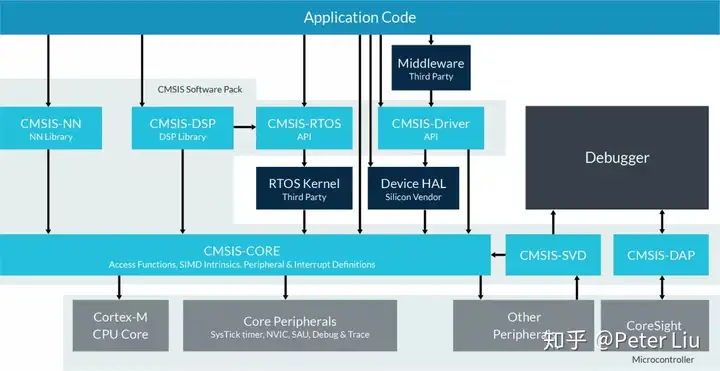 CMSIS-NN是最近加入CMSIS家族的新成员,她的加入大大缓解了基于MCU的神经网络相关软件的优化压力。 CMSIS-NN通过对神经网络中所需要的关键函数进行优化,以达到强化性能的目的。比如,通过查表避免激活函数计算等,同时采用定点运算(8/16bits)替代浮点运算也能够显著减少内存消耗。更加值得推荐的是,在程序中使用CMSIS-NN添加神经网络也非常方便,只需要调用相应的API即可完成。 因此,针对于Arm Cortex-M系列处理器内核,如果您想要强化性能并且减少内存消耗,CMSIS-NN会是您最好的朋友。基于CMSIS-NN函数库的神经网络推理运算,对于运行时间/吞吐量,相比未用CMSIS-NN函数库,将会有4.6X的提升,而对于能效将有4.9X的提升。 CMSIS-NN函数库包含有两部分:NNFunctions和NNSupportFunctions。其中,NNFunctions包含了实现神经网络常用操作的API,比如卷积(convolution),深度可分离卷积(depthwise separable convolution),全连接(即内积inner-product),池化(polling)和激活(activation)。这些函数的有序组合就摇身一变成为了神经网络的中枢系统,软件层应用程序通过调用这些函数,实现神经网络的推理应用。 NNSupportFunctions函数集包括不同的实用函数,如NNFunctions中使用的数据转换和激活功能表。正如其名,这组函数为NN算法提供更基本的操作。此外,如果CMSIS-NN的功能扩展,也可以用它们构造更复杂的NN模块,例如,长期短时记忆(LSTM)或门控循环单元(GRU)。 CMSIS-NN的API是直接对接到CPU的底层库,API要求的参数往往多达十余个,特别是还要求提供权重表。手动调用这些API实现动辄十余层的神经网络枯燥、耗时并且易错,所以一般用上一期提到的部署工具实现模型转代码或者通过执行引擎来调用CMSIS-NN。 下图是CMSIS-NN的框架图: 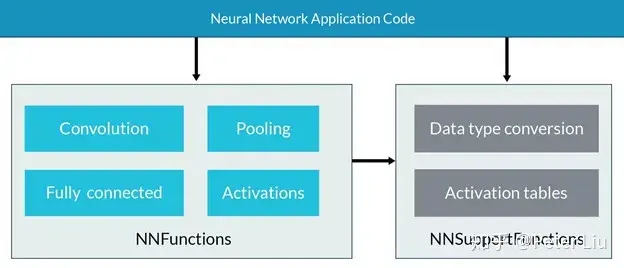
语音识别方案这里教大家从语音前端处理、基于统计学语音识别和基于深度学习语音识别等方面阐述语音识别的原理。 语音识别的本质就是将语音序列转换为文本序列,其常用的系统框架如下:  接下来对语音识别相关技术进行介绍,为了便于整体理解,首先,介绍语音前端信号处理的相关技术,然后,解释语音识别基本原理,并展开到声学模型和语言模型的叙述。 1. 前端信号处理 前端的信号处理是对原始语音信号进行的相关处理,使得处理后的信号更能代表语音的本质特征,相关技术点如下表所述: a.语音活动检测: 语音活动检测(Voice Activity Detection, VAD)用于检测出语音信号的起始位置,分离出语音段和非语音(静音或噪声)段。VAD算法大致分为三类:基于阈值的VAD、基于分类器的VAD和基于模型的VAD。 b.降噪: 在生活环境中通常会存在例如空调、风扇等各种噪声,降噪算法目的在于降低环境中存在的噪声,提高信噪比,进一步提升识别效果。常用降噪算法包括自适应LMS和维纳滤波等。 c.回声消除: 回声存在于双工模式时,麦克风收集到扬声器的信号,比如在设备播放音乐时,需要用语音控制该设备的场景。回声消除通常使用自适应滤波器实现的,即设计一个参数可调的滤波器,通过自适应算法(LMS、NLMS等)调整滤波器参数,模拟回声产生的信道环境,进而估计回声信号进行消除。 d.混响消除: 语音信号在室内经过多次反射之后,被麦克风采集,得到的混响信号容易产生掩蔽效应,会导致识别率急剧恶化,需要在前端处理。混响消除方法主要包括:基于逆滤波方法、基于波束形成方法和基于深度学习方法等。 e.声源定位: 麦克风阵列已经广泛应用于语音识别领域,声源定位是阵列信号处理的主要任务之一,使用麦克风阵列确定说话人位置,为识别阶段的波束形成处理做准备。声源定位常用算法包括:基于高分辨率谱估计算法(如MUSIC算法),基于声达时间差(TDOA)算法,基于波束形成的最小方差无失真响应(MVDR)算法等。 f.波束形成: 波束形成是指将一定几何结构排列的麦克风阵列的各个麦克风输出信号,经过处理(如加权、时延、求和等)形成空间指向性的方法,可用于声源定位和混响消除等。波束形成主要分为:固定波束形成、自适应波束形成和后置滤波波束形成等。 2. 语音识别的基本原理 已知一段语音信号,处理成声学特征向量之后表示为,其中表示一帧数据的特征向量,将可能的文本序列表示为,其中表示一个词。语音识别的基本出发点就是求,即求出使最大化的文本序列。将通过贝叶斯公式表示为: 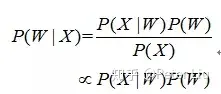 其中,称之为声学模型,称之为语言模型。大多数的研究将声学模型和语言模型分开处理,并且,不同厂家的语音识别系统主要体现在声学模型的差异性上面。此外,基于大数据和深度学习的端到端(End-to-End)方法也在不断发展,它直接计算 ,即将声学模型和语言模型作为整体处理。本文主要对前者进行介绍。 3. 声学模型 声学模型是将语音信号的观测特征与句子的语音建模单元联系起来,即计算。我们通常使用隐马尔科夫模型(Hidden Markov Model,HMM)解决语音与文本的不定长关系,比如下图的隐马尔科夫模型中。 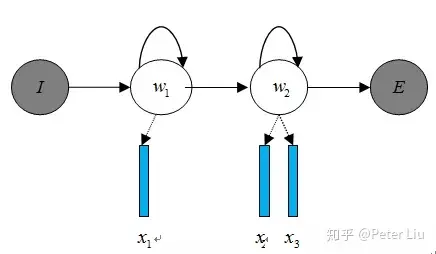 将声学模型表示为: 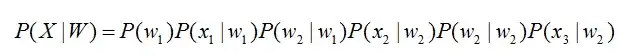 其中,初始状态概率和状态转移概率可用通过常规统计的方法计算得出,发射概率 )可以通过混合高斯模型GMM或深度神经网络DNN求解。 传统的语音识别系统普遍采用基于GMM-HMM的声学模型,示意图如下: 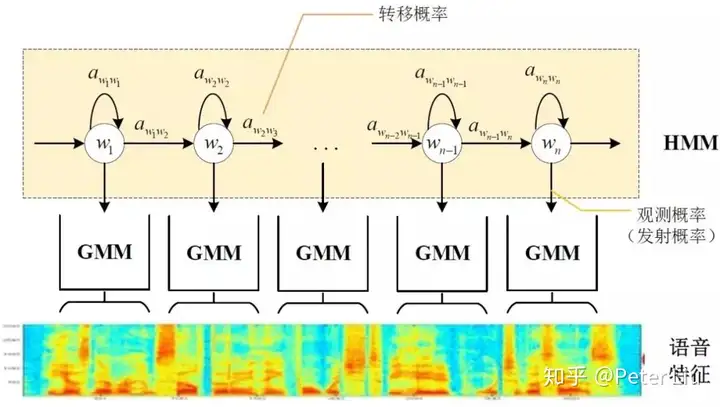 其中,表示状态转移概率,语音特征表示,通过混合高斯模型GMM建立特征与状态之间的联系,从而得到发射概率,并且,不同的状态对应的混合高斯模型参数不同。基于GMM-HMM的语音识别只能学习到语音的浅层特征,不能获取到数据特征间的高阶相关性,DNN-HMM利用DNN较强的学习能力,能够提升识别性能,其声学模型示意图如下: 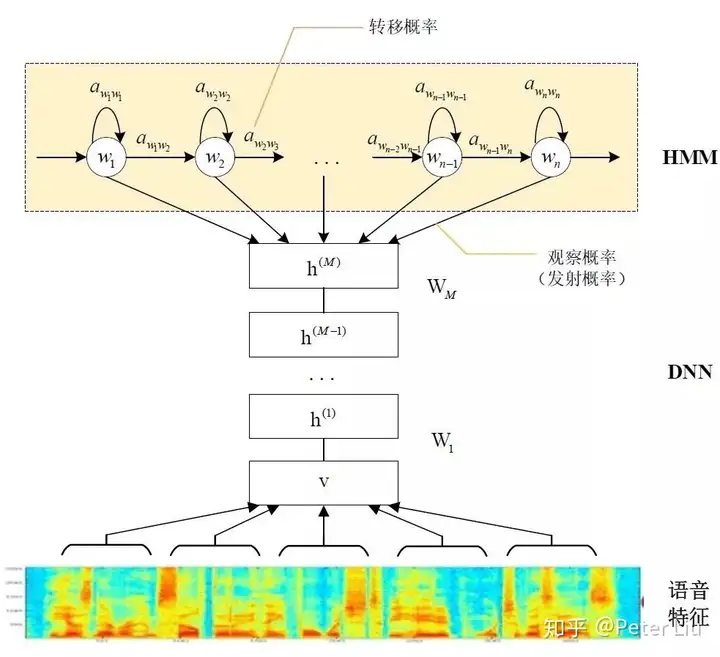 GMM-HMM和DNN-HMM的区别在于用DNN替换GMM来求解发射概率,GMM-HMM模型优势在于计算量较小且效果不俗。DNN-HMM模型提升了识别率,但对于硬件的计算能力要求较高。因此,模型的选择可以结合实际的应用调整。 4. 语言模型 语音识别中的语言模型也用于处理文字序列,它是结合声学模型的输出,给出概率最大的文字序列作为语音识别结果。由于语言模型是表示某一文字序列发生的概率,一般采用链式法则表示,如是由组成,则可由条件概率相关公式表示为: 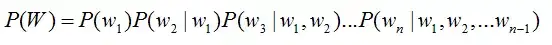 由于条件太长,使得概率的估计变得困难,常见的做法是认为每个词的概率分布只依赖于前几个出现的词语,这样的语言模型成为n-gram模型。在n-gram模型中,每个词的概率分布只依赖于前面n-1个词。例如在trigram(n取值为3)模型,可将上式化简: 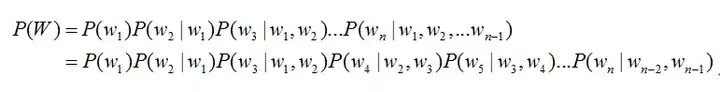
根据上面的算法原理把训练的模型移植到cortex-m7中,demo如下: 语音识别演示demo 人脸识别方案我们先来看一张图: 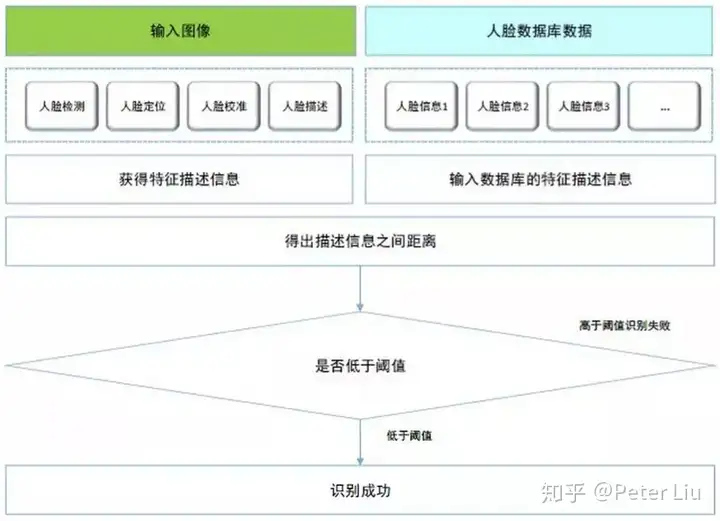 可以看出人脸识别算法包括人脸检测、人脸定位、人脸校准、人脸比对等。废话少说我们直接进入主题。 1. 人脸识别 人脸检测算法繁多,我们采用由粗到精的高效方式,即先用计算量小的特征快速过滤大量非人脸窗口图像,然后用复杂特征筛选人脸。这种方式能快速且高精度的检测出正脸(人脸旋转不超过45度)。该步骤旨在选取最佳候选框,减小非人脸区域的处理,从而减小后续人脸校准及比对的计算量。 
2. 人脸定位 面部特征点定位在人脸识别、表情识别、人脸动画等人脸分析任务中至关重要的一环。人脸定位算法需要选取若干个面部特征点,点越多越精细,但同时计算量也越大。兼顾精确度和效率,一般选用双眼中心点、鼻尖及嘴角五个特征点。 3. 人脸校准 本步骤目的是摆正人脸,将人脸置于图像中央,减小后续比对模型的计算压力,提升比对的精度。主要利用人脸定位获得的5个特征点(人脸的双眼、鼻尖及嘴角)获取仿射变换矩阵,通过仿射变换实现人脸的摆正。 目标图形以(x,y)为轴心顺时针旋转Θ弧度,变换矩阵为: 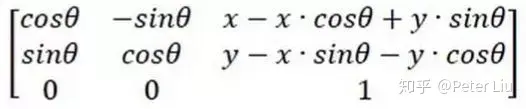 人脸校准的效果如图所示: 
4. 人脸对比 人脸比对和人脸身份认证的前提是需要提取人脸独有的特征点信息。在人脸校准之后可以利用深度神经网络,将输入的人脸进行特征提取。如将112×112×3的脸部图像提取256个浮点数据特征信息,并将其作为人脸的唯一标识。在注册阶段把256个浮点数据输入系统,而认证阶段则提取系统存储的数据与当前图像新生成的256个浮点数据进行比对最终得到人脸比对结果。 通过神经网络算法得到的特征点示意图如下:  而人脸比对则是对256个浮点数据之间进行距离运算。计算方式常用的有两种,一种是欧式距离,一种是余弦距离。x,y向量欧式距离定义如下: 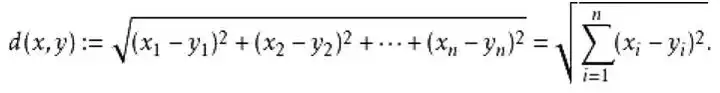 x,y向量之间余弦距离定义如下: 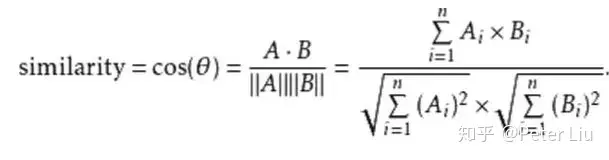 余弦距离或欧式距离越大,则两个特征值相似度越低,属于同一个人的可能性越小。如下图,他们的脸部差异值为0.4296 大于上文所说的该模型最佳阈值0.36,此时判断两人为不同的人,可见结果是正确的。  把归一化为-1到1的图像数据、特征点提取模型的参数还有人脸数据库输入到人脸比对的函数接口face_recgnition,即可得人脸认证结果。 最后根据上面的算法原理把训练的模型移植到cortex-m7中,demo如下: 人脸识别演示demo
| 


 |Archiver|手机版|小黑屋|firemail
( 粤ICP备15085507号-1 )
|Archiver|手机版|小黑屋|firemail
( 粤ICP备15085507号-1 )




 发表于 2023-5-13 18:24:18
发表于 2023-5-13 18:24:18

 收藏
收藏