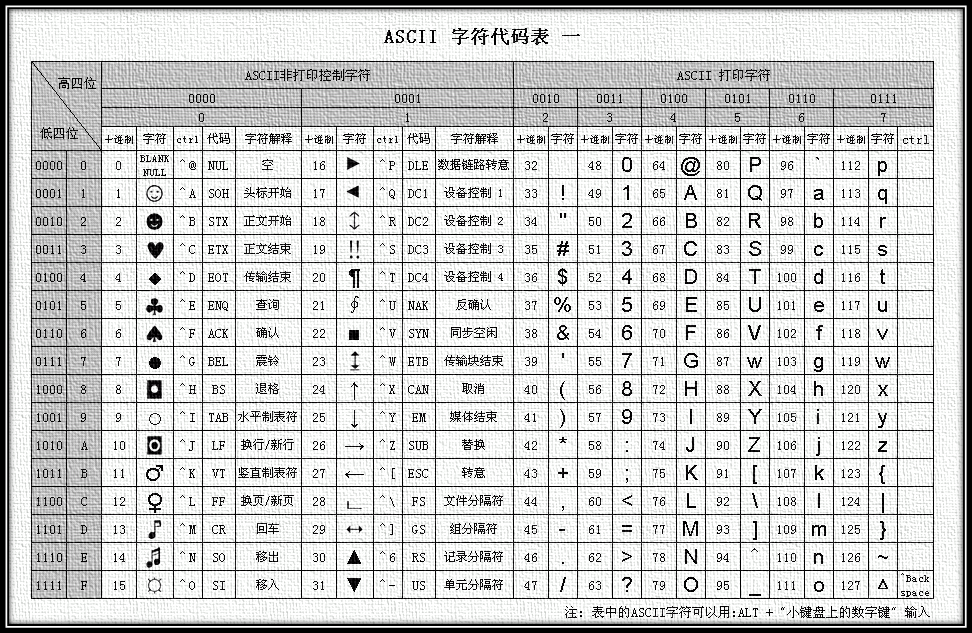
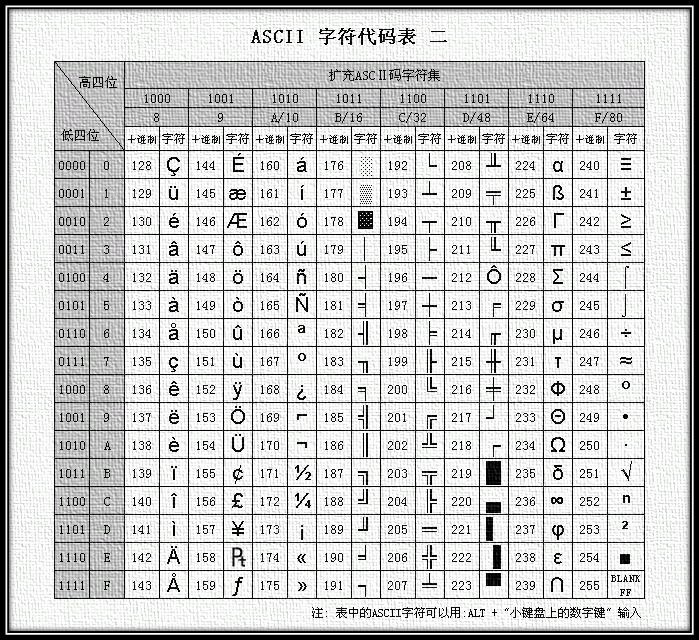
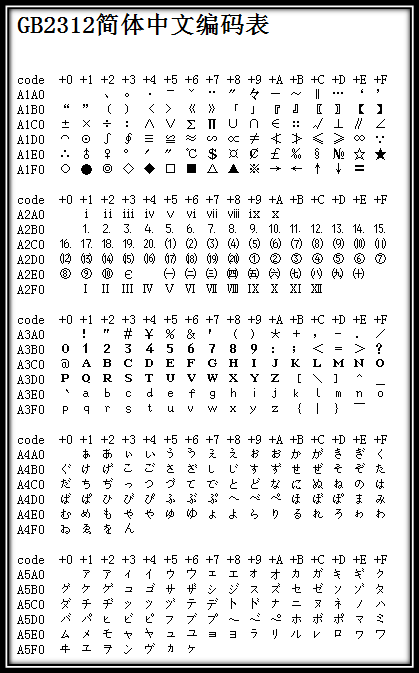
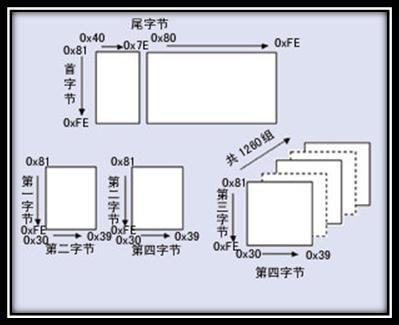
汉字收录范围包含繁体汉字以及日韩汉字
图4 GB18030编码总体结构
2.3. BIG5字符集&编码Big5,又称为
大五码或
五大码,是使用
繁体中文(正体中文)社区中最常用的电脑
汉字字符集标准,共收录13,060个汉字。中文码分为
内码及
交换码两类,Big5属中文内码,知名的中文交换码有
CCCII、
CNS11643。Big5虽普及于
台湾、
香港与
澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是
业界标准。
倚天中文系统、
Windows等主要系统的字符集都是以Big5为基准,但厂商又各自增加不同的造字与造字区,派生成多种不同版本。
2003年,Big5被收录到CNS11643中文标准交换码的附录当中,取得了较正式的地位。这个最新版本被称为Big5-2003。
Big5码是一套
双字节字符集,使用了双八码存储方法,以两个字节来安放一个字。第一个字节称为"高位字节",第二个字节称为"低位字节"。"高位字节"使用了0x81-0xFE,"低位字节"使用了0x40-0x7E,及0xA1-0xFE。在Big5的分区中:
0x8140-0xA0FE | |
0xA140-0xA3BF | 标点符号、希腊字母及特殊符号,包括在0xA259-0xA261,安放了九个计量用汉字:兙兛兞兝兡兣嗧瓩糎。 |
| |
0xA440-0xC67E | |
| |
0xC940-0xF9D5 | |
| |
Unicode字符集&UTF编码
3.伟大的创想Unicode——不得不单独说Unicode
像天朝一样,当计算机传到世界各个国家时,为了适合当地语言和字符,设计和实现类似GB232/GBK/GB18030/BIG5的编码方案。这样各搞一套,在本地使用没有问题,一旦出现在网络中,由于不兼容,互相访问就出现了乱码现象。
为了解决这个问题,一个伟大的创想产生了——Unicode。Unicode编码系统为表达任意语言的任意字符而设计。它使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph)。每个数字代表唯一的至少在某种语言中使用的符号。(并不是所有的数字都用上了,但是总数已经超过了65535,所以2个字节的数字是不够用的。)被几种语言共用的字符通常使用相同的数字来编码,除非存在一个在理的语源学(etymological)理由使之不这样做。不考虑这种情况的话,每个字符对应一个数字,每个数字对应一个字符。即不存在二义性。不再需要记录"模式"了。U+0041总是代表'A',即使这种语言没有'A'这个字符。
在
计算机科学领域中,
Unicode(
统一码、
万国码、
单一码、
标准万国码)是业界的一种标准,它可以使电脑得以体现世界上数十种文字的系统。Unicode 是基于
通用字符集(Universal Character Set)的标准来发展而来,并且同时也以书本的形式
[1]对外发表。Unicode 还不断在扩增, 每个新版本插入更多新的字符。直至目前为止的第六版,Unicode 就已经包含了超过十万个
字符(在
2005年,Unicode 的第十万个字符被采纳且认可成为标准之一)、一组可用以作为视觉参考的代码图表、一套编码方法与一组标准
字符编码、一套包含了上标字、下标字等字符特性的枚举等。Unicode 组织(The Unicode Consortium)是由一个非营利性的机构所运作,并主导 Unicode 的后续发展,其目标在于:将既有的字符编码方案以Unicode 编码方案来加以取代,特别是既有的方案在多语言环境下,皆仅有有限的空间以及不兼容的问题。
(可以这样理解:Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三种字符编码方案。)
3.1.UCS & UNICODE通用字符集(Universal Character Set,
UCS)是由
ISO制定的
ISO 10646(或称
ISO/IEC 10646)标准所定义的标准字符集。历史上存在两个独立的尝试创立单一字符集的组织,即国际标准化组织(ISO)和多语言软件制造商组成的
统一码联盟。前者开发的 ISO/IEC 10646 项目,后者开发的
统一码项目。因此最初制定了不同的标准。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都存在,并独立地公布各自的标准。但统一码联盟和ISO/IEC JTC1/SC2都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。在发布的时候,Unicode一般都会采用有关字码最常见的字型,但ISO 10646一般都尽可能采用
Century字型。
3.2.UTF-32上述使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph),每个数字代表唯一的至少在某种语言中使用的符号的编码方案,称为UTF-32。UTF-32又称
UCS-4是一种将
Unicode字符编码的协定,对每个字符都使用4字节。就空间而言,是非常没有效率的。
这种方法有其优点,最重要的一点就是可以在常数时间内定位字符串里的第N个字符,因为第N个字符从第4×Nth个字节开始。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。
3.3.UTF-16尽管有Unicode字符非常多,但是实际上大多数人不会用到超过前65535个以外的字符。因此,就有了另外一种Unicode编码方式,叫做UTF-16(因为16位 = 2字节)。UTF-16将0–65535范围内的字符编码成2个字节,如果真的需要表达那些很少使用的"星芒层(astral plane)"内超过这65535范围的Unicode字符,则需要使用一些诡异的技巧来实现。UTF-16编码最明显的优点是它在空间效率上比UTF-32高两倍,因为每个字符只需要2个字节来存储(除去65535范围以外的),而不是UTF-32中的4个字节。并且,如果我们假设某个字符串不包含任何星芒层中的字符,那么我们依然可以在常数时间内找到其中的第N个字符,直到它不成立为止这总是一个不错的推断。其编码方法是: